Until recently, Yang and Ramanan’s method has been a state-of-the-art method for pose estimation in monocular images.
Although there have been other algorithms that have improved Yang and Ramanan’s model, such as Wang and Li (2013); Pishchulin et al. (2013); Ramakrishna et al. (2014), all these methods, including Yang and Ramanan’s, use a mixture of parts for only the RGB dimension of channels.
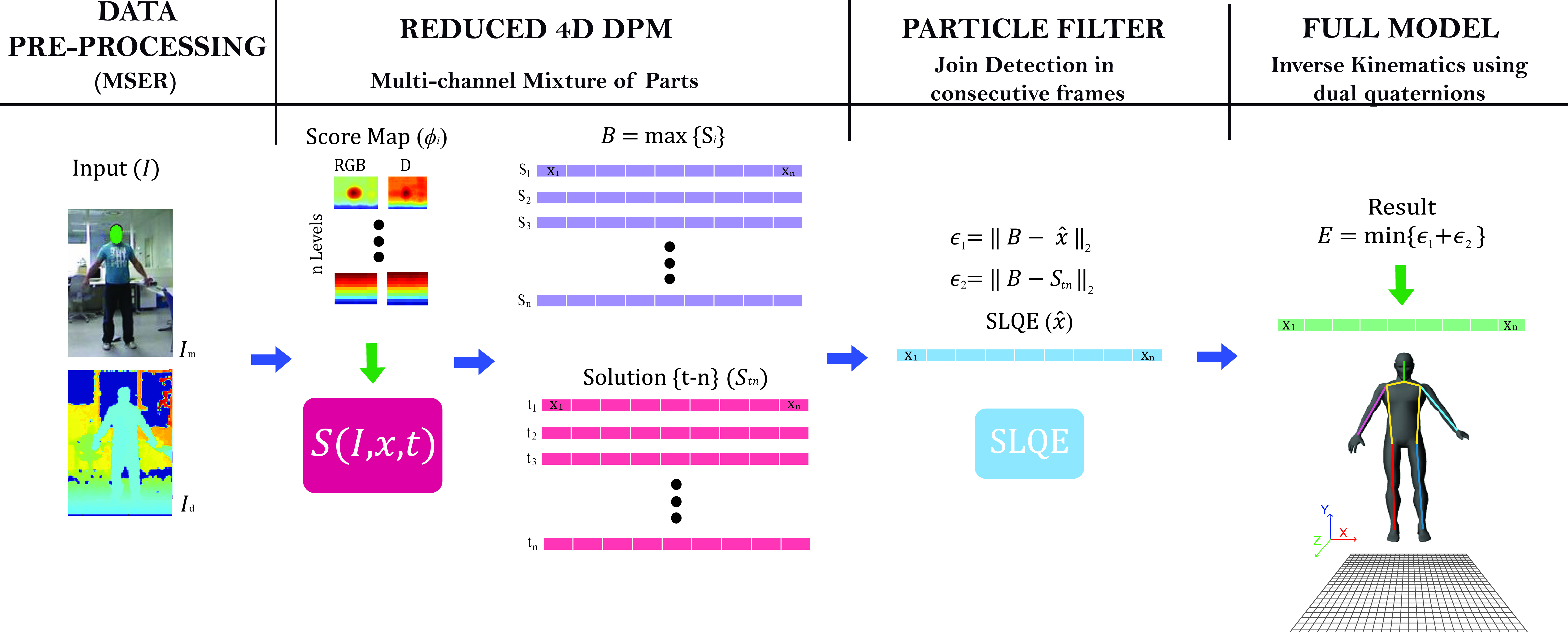
Conversely, our method uses a multi-channel mixture of parts model that allows us to extend the number of mixtures of parts to the depth dimension of RGBD images.
The depth channel increases time complexity, but this disadvantage has been solved by cutting the number of joints modeled in our 4D-DPM method. Hence our method differs significantly from other previous methods in many important ways.
The name 4D-DPM is the abreviaton of «4-Domensional Deformable Part Model», where we use 4 dimenions, RGB and Depth, for pose estimation using DPM.
The method presented introduce some models on the original DPM to performe the results. We add a MSER model to delate the background on the image. The number of parts from the original DPM model is reducet from 14 to 10 for speed up the algorithm because we are increasing it after add the depth channel. A kinematics model using dual quaternions it’s used for infer on the number of parts to obtain again the 14 parts. A particle filter model it’s used for tracking the pose estimation along the time introducing restrictions as detect colisions and limits on joint articulations.
A more detailed explanation can be found in the publications mentioned in section «Publications».